MinIO架构简介 面向未来的高性能数据处理与存储服务
在当今数据驱动的时代,高效、可扩展且经济实惠的对象存储解决方案已成为企业和开发者的核心需求。MinIO,作为一款高性能、云原生的对象存储系统,以其简洁的架构、与Amazon S3 API的完全兼容性以及卓越的性能,在数据处理和存储服务领域脱颖而出。本文将深入浅出地介绍MinIO的核心架构、数据处理能力及其在现代云原生环境中的应用。
一、 核心架构:简洁与分布式之美
MinIO的架构设计遵循“简单性”这一核心原则,摒弃了传统存储系统的复杂性,使其易于部署、运维和扩展。其核心架构基于以下几个关键组件和理念:
- 纯软件定义: MinIO完全运行在标准硬件上,无需专用的存储设备或复杂的网络配置。它利用服务器的本地磁盘(HDD/SSD/NVMe)构建统一的存储资源池。
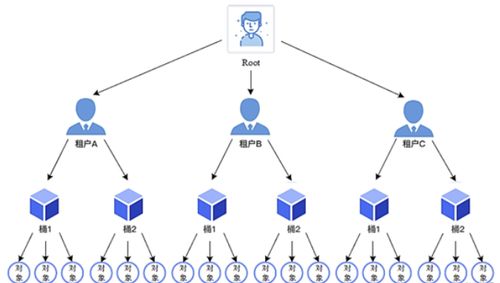
- 分布式设计: MinIO原生支持分布式部署。一个MinIO集群由多个服务器(Server) 组成,每个服务器即一个独立的进程。集群中的存储空间被划分为多个纠删码集(Erasure Set)。数据对象并非完整地存储在某一个磁盘上,而是通过纠删码(Erasure Coding)技术,被切分成数据块和校验块,并分散存储在纠删码集内的多个磁盘(驱动器,Drive)中。这种设计不仅提供了极高的数据耐久性(通常可承受高达一半的驱动器同时故障而不丢失数据),还实现了出色的读写性能。
- 无元数据数据库: 与许多传统对象存储系统不同,MinIO没有独立的外部元数据数据库(如MySQL或PostgreSQL)。其所有元数据(如桶名、对象名、访问策略)都与数据对象本身一起,以相同的纠删码机制进行存储和管理。这消除了单点故障,简化了架构,并确保了强一致性。
二、 数据处理能力:超越静态存储
MinIO不仅仅是一个静态的存储仓库,它集成了强大的数据处理功能,使其能够成为数据湖、AI/ML工作流和实时分析的数据枢纽。
- 与计算框架的深度集成:
- Spark & Presto: MinIO可以作为Hadoop HDFS的替代品,无缝对接Apache Spark、Presto等大数据处理框架,进行大规模数据分析和ETL作业。
- TensorFlow & PyTorch: 在机器学习和深度学习场景中,MinIO是训练数据集、模型文件和检查点的理想存储后端,支持高性能的数据读取。
- MinIO Select: 这是一个革命性的功能,允许用户直接在存储层对对象(如CSV、JSON、Parquet格式)执行简单的SQL查询(如SELECT、WHERE)。应用程序无需下载整个对象,只需提取所需的数据列和行,极大地减少了网络传输和客户端处理负担,提升了分析效率。
- 对象生命周期管理与版本控制: MinIO支持自动化的对象生命周期策略,例如将旧数据转移到更经济的存储层或自动删除过期数据。其对象版本控制功能可以防止数据被意外覆盖或删除,为数据安全提供了有力保障。
三、 作为现代数据处理与存储服务的关键特性
- 高性能: MinIO是为性能而生的。其极简的Golang实现、无锁设计以及对最新硬件(如NVMe SSD)的优化,使其能够提供极高的吞吐量和极低的延迟,特别适合存储非结构化数据(图片、视频、日志、备份等)。
- 云原生与Kubernetes原生: MinIO是CNCF的孵化项目,与Kubernetes生态深度集成。它可以通过Operator轻松部署和管理,实现存储的弹性伸缩,完美适配微服务和无服务器架构。
- 安全性: 提供企业级的安全特性,包括静态数据加密(Server-Side Encryption with KMS)、传输层加密(TLS)、基于身份的访问控制(IAM)以及精细的存储桶策略,确保数据在存储和传输过程中的安全。
- 可观测性: 内置与Prometheus和Grafana的集成,提供详细的指标监控(如存储容量、请求率、延迟),便于运维团队进行性能分析和故障排查。
###
MinIO通过其优雅的分布式架构、强大的数据处理能力和云原生的设计理念,重新定义了对象存储。它不仅是AWS S3的一个高性能开源替代品,更是一个能够支撑起从大数据分析、人工智能到现代应用备份等多样化工作负载的综合性数据基础设施层。无论是构建私有云、混合云还是边缘计算环境,MinIO都提供了一个简单、强大且经济高效的数据处理和存储解决方案。随着数据量的持续爆炸式增长,MinIO的架构优势将使其在未来的数据生态中扮演愈发重要的角色。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/64.html
更新时间:2026-06-19 16:38:53