字节跳动流式数仓与实时服务分析的融合实践 数据处理与存储服务的演进之路
在当今大数据与人工智能驱动的时代,数据的实时价值日益凸显。字节跳动作为全球领先的科技公司,面对海量、高并发的数据流,构建了一套高效、稳定的流式数仓与实时服务分析体系。本文将探讨其背后的核心思考与实践,特别是在数据处理与存储服务方面的创新与挑战。
一、流式数仓的核心价值:从批处理到实时分析的跨越
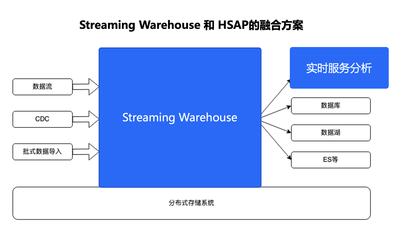
传统的数据仓库多基于批处理模式,数据从产生到分析往往存在数小时甚至数天的延迟。在推荐系统、广告投放、风险控制等场景中,实时性直接关系到用户体验与商业效益。字节跳动通过流式数仓的构建,实现了数据从产生到消费的秒级甚至毫秒级延迟,使业务团队能够基于最新数据快速决策。流式数仓的核心在于将数据流视为“持续流动的河流”,而非“静态的湖泊”,从而支持实时ETL、流式聚合与即时查询。
二、数据处理服务:高吞吐、低延迟的技术架构
字节跳动的数据处理服务面临两大挑战:一是每日处理的数据量高达PB级别,二是需要保证毫秒级的端到端延迟。为此,团队采用了分层架构:
- 数据采集层:通过自研的LogAgent与Kafka集群,实现分布式、高可用的数据采集与缓冲,支持每秒百万级的事件吞吐。
- 流式计算层:基于Apache Flink构建实时计算引擎,支持复杂事件处理(CEP)与状态管理,确保数据处理的准确性与一致性。通过动态资源调度与故障自动恢复,保障服务稳定性。
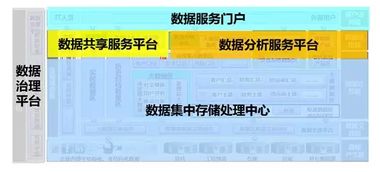
- 数据集成层:将流式数据与批处理数据融合,通过Lambda或Kappa架构,提供统一的数据视图,避免数据孤岛。
三、存储服务设计:平衡性能、成本与可扩展性
存储是流式数仓的基石。字节跳动的存储服务遵循“分层存储、智能缓存”原则:
- 热存储:使用分布式内存数据库(如Redis)或SSD存储,存放高频访问的实时数据,确保低延迟查询。
- 温存储:采用列式存储(如Apache Druid或ClickHouse),支持实时聚合分析,兼顾查询性能与存储成本。
- 冷存储:将历史数据归档至HDFS或对象存储(如字节跳动自研的ByteStorage),通过压缩与索引优化,降低长期存储成本。
存储服务通过数据分区、副本机制与弹性扩缩容,应对业务峰值压力,实现99.99%的可用性。
四、实时服务分析的实践案例:推荐系统的优化
以字节跳动的推荐系统为例,流式数仓与实时服务分析发挥了关键作用:
- 实时特征计算:用户点击、观看时长等行为数据实时流入Flink引擎,生成动态用户画像,并在毫秒内更新推荐模型。
- A/B测试即时反馈:通过流式数据管道,新算法上线后的效果数据可在分钟级内呈现,加速迭代周期。
- 异常检测与容灾:实时监控数据流中的异常指标(如流量突增或延迟飙升),自动触发告警或降级策略,保障服务连续性。
五、未来展望:云原生与智能化的演进
随着业务全球化与场景复杂化,字节跳动在数据处理与存储服务上持续创新:
- 云原生架构:容器化部署与Serverless计算将进一步提升资源利用率与弹性能力。
- 智能化运维:通过AI算法预测数据流量趋势,自动优化存储策略与计算资源分配。
- 生态开放:将内部验证的技术(如流式计算框架)通过火山引擎等平台对外开放,赋能行业数字化转型。
###
字节跳动的流式数仓与实时服务分析体系,不仅是技术栈的堆砌,更是对数据价值挖掘的深刻理解。通过数据处理与存储服务的精细化设计,公司在海量数据洪流中实现了敏捷响应与智能决策。这一实践为行业提供了宝贵参考,也预示着实时数据驱动将成为未来企业竞争力的核心要素。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/37.html
更新时间:2026-06-19 17:45:52