自然语言处理与对话技术研究进展及个人思考
自然语言处理(NLP)作为人工智能领域的重要分支,近年来在人机对话技术驱动下取得显著进展。本文结合个人研究经验,探讨NLP技术的演进脉络、现状挑战与未来方向,并分享在数据处理与存储服务方面的实践思考。
一、自然语言处理技术发展脉络
自然语言处理技术经历了从规则驱动到统计建模,再到深度学习的三次范式变迁。早期基于词典和语法规则的符号主义方法受限于语言复杂性,难以处理歧义与多样性。21世纪初统计学习方法兴起,通过隐马尔可夫模型、条件随机场等算法显著提升了词性标注、命名实体识别等任务的性能。2013年后,以Word2Vec为代表的词向量技术将语义信息编码为稠密向量,为深度学习方法奠定基础。2018年BERT模型突破性采用Transformer架构与预训练-微调范式,在GLUE等基准测试中刷新多项记录,标志着NLP进入预训练大模型时代。
二、人机对话技术的关键突破
人机对话系统可分为任务导向型与开放域对话两大类别。任务型对话通过意图识别、槽位填充等技术实现精准服务,已在客服、智能家居等场景规模化落地。开放域对话则更注重语义理解与生成质量,GPT系列模型通过自回归生成实现了上下文连贯的多轮对话。值得关注的技术进展包括:
- 跨模态对话融合视觉、语音等多模态信息
- 知识增强对话通过外部知识库提升回答准确性
- 情感感知技术使对话系统能识别用户情绪并调整响应策略
- 持续学习机制让系统在使用过程中不断优化对话能力
三、数据处理与存储的技术实践
高质量数据是NLP模型的基石。在数据采集阶段需注重:
- 多源数据融合:整合结构化与非结构化数据
- 数据标注策略:结合主动学习与众包标注提升效率
- 隐私保护机制:采用差分隐私、联邦学习等技术
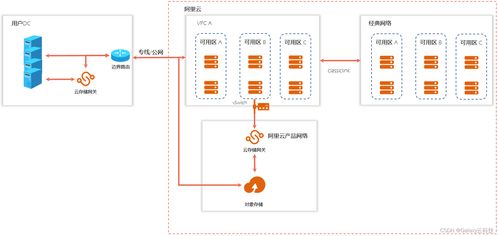
数据存储层面,建议采用分层存储架构:
- 热数据使用内存数据库支撑实时对话
- 温数据通过分布式文件系统存储训练样本
- 冷数据归档至对象存储降低成本
在SegmentFault等技术社区实践中,我们构建了基于Elasticsearch的语义检索系统,支持千万级技术文档的智能问答,通过向量化存储实现毫秒级相似度匹配。
四、挑战与未来展望
当前技术仍面临诸多挑战:
1. 少样本学习:如何降低对标注数据的依赖
2. 可解释性:增强模型决策过程的透明度
3. 伦理对齐:避免生成有害内容与偏见放大
4. 能耗优化:降低大模型训练与推理的资源消耗
未来发展方向可能集中于:
- 构建具身智能实现与现实世界的交互理解
- 发展因果推理能力超越相关性学习
- 探索神经符号融合的新范式
- 推动轻量化模型在边缘设备的部署
自然语言处理正从感知智能迈向认知智能,人机对话技术将深度重塑人机交互范式。作为研究者,我们既要拥抱技术革新,也需保持对技术伦理的审慎思考,在数据处理、模型研发与应用落地间寻求平衡,最终构建真正理解人类意图的智能对话系统。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/28.html
更新时间:2026-06-19 16:47:12